Weltweit erste KI-Modelle für programmierbare Gen-Insertion vorgestellt
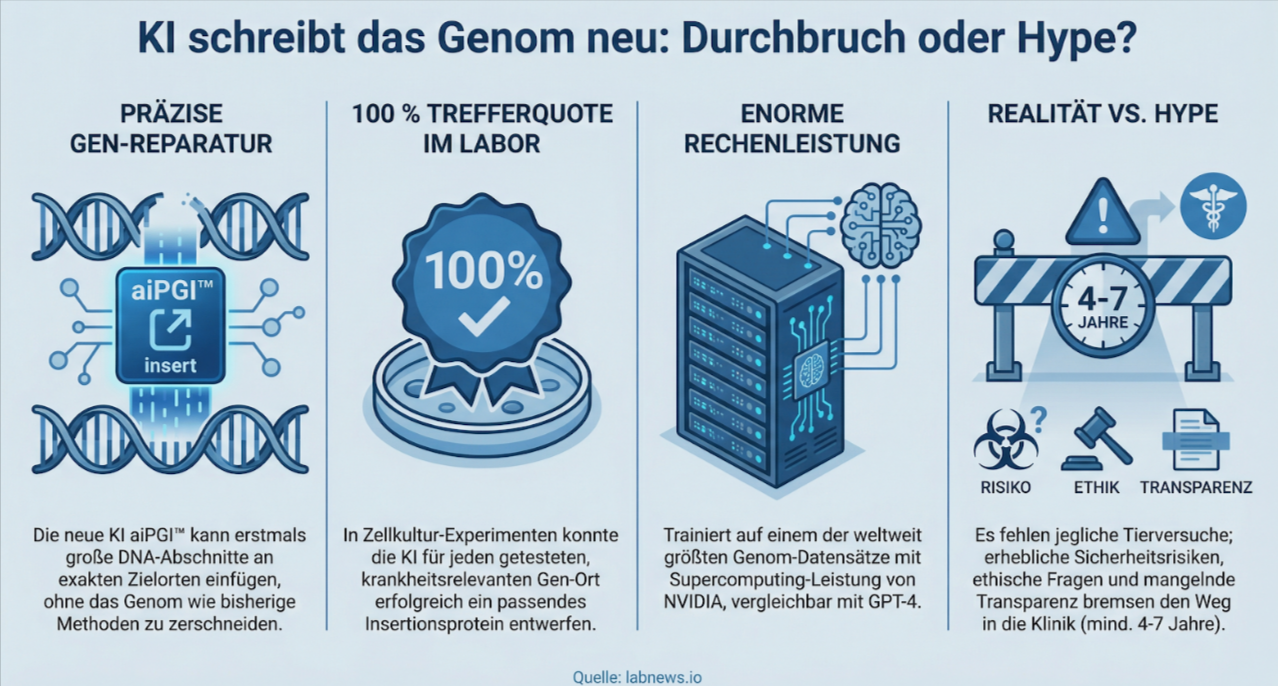
Am 12. Januar 2026 verkündete das britisch-amerikanische KI-Biotech-Unternehmen Basecamp Research einen technischen Meilenstein, der in der Fachwelt für erhebliche Aufregung sorgt: Die Entwicklung der ersten KI-Modelle, die eine programmierbare, ortsspezifische Insertion großer DNA-Sequenzen in das menschliche Genom ermöglichen sollen. Das System mit dem Namen aiPGI™ (AI-Programmable Gene Insertion) basiert auf der EDEN-Familie evolutionärer KI-Modelle, die in enger Kooperation mit NVIDIA auf dem proprietären Datensatz BaseData™ trainiert wurden – dem nach Angaben des Unternehmens größten ethisch gesammelten Genom-Datensatz der Welt. Gleichzeitig sicherte sich Basecamp Research eine Pre-Series-C-Investition von NVentures, dem Venture-Capital-Arm von NVIDIA.
Die Ankündigung verspricht nichts Geringeres als eine neue Generation kurativer Zell- und Gentherapien für Krebs und monogene Erbkrankheiten. Doch hinter den beeindruckenden Laborergebnissen und den Superlativen stehen erhebliche wissenschaftliche, ethische und regulatorische Hürden, die den Weg in die Klinik noch sehr lang und unsicher machen.
Der technische Durchbruch: Von CRISPR zu programmierbarer Insertion
Die zentrale Limitation bisheriger CRISPR-Systeme liegt in ihrer Unfähigkeit, große DNA-Fragmente (mehrere Kilobasen) ohne Doppelstrangbruch präzise an definierten Orten einzubauen. CRISPR-Cas9 schneidet das Genom und nutzt die zelleigene Reparaturmaschinerie (HDR), was ineffizient, fehleranfällig und positionsabhängig ist. Basecamp Research geht einen anderen Weg: Die KI entwirft neuartige Enzyme (vermutlich Transposasen oder Integrasen), die große therapeutische DNA-Sequenzen an beliebigen, vorgegebenen genomischen Zielorten einbauen können – ohne dass ein Doppelstrangbruch notwendig ist.
Die Modelle wurden mit über 10 Billionen Tokens evolutionärer DNA-Sequenzen aus mehr als einer Million neu entdeckter Arten trainiert. Diese Daten stammen aus einem fünfjährigen globalen Sammelprojekt in 28 Ländern und fünf Kontinenten. Der größte EDEN-Modell wurde mit 1,95 × 10²⁴ FLOPs auf einem Cluster von 1.008 NVIDIA Hopper-GPUs trainiert – eine Rechenleistung, die in die Liga von GPT-4 gehört und zu den größten jemals für biologische Modelle berichteten gehört.
In Laborversuchen (veröffentlicht in einem Paper mit NVIDIA, Microsoft und akademischen Co-Autoren) erreichten die Modelle eine Trefferquote von 100 %: Für jeden getesteten krankheitsrelevanten Zielort im humanen Genom konnte mindestens ein aktives Insertionsprotein entworfen werden. Besonders eindrucksvoll: Die Integration von CAR-Konstrukten in primäre humane T-Zellen an neuartigen „safe-harbour“-Sites führte zu CAR-T-Zellen mit über 90 % Tumorkilling in In-vitro-Assays.

Parallelentwicklung: Antimikrobielle Peptide gegen Superkeime
Die gleiche EDEN-Plattform zeigte ihre Vielseitigkeit bei der De-novo-Design von antimikrobiellen Peptiden (AMPs). In Kooperation mit Prof. César de la Fuente (University of Pennsylvania) wurde eine fokussierte Bibliothek generiert, von der 97 % der Kandidaten im Labor antibakterielle Aktivität zeigten. Die besten Moleküle erwiesen sich als hochpotent gegen multiresistente „critical-priority“-Erreger (WHO-Liste), darunter Carbapenem-resistente Enterobakterien und Acinetobacter baumannii.
Dieser Dual-Use-Aspekt unterstreicht die Stärke der evolutionären KI-Modelle: Sie lernen nicht nur Sequenzmuster, sondern abstrakte „Sprache“ der Biologie und können für sehr unterschiedliche Designaufgaben eingesetzt werden.
Kritische Bewertung: Hype vs. Realität
Trotz der beeindruckenden Zahlen bleibt die Ankündigung mit erheblichen Vorbehalten zu betrachten.
- Präklinische Phase vs. Klinik
Alle Daten stammen aus In-vitro- und primären Zellkulturen. Es fehlen jegliche Tierversuche (insbesondere in vivo-Insertionseffizienz, Off-Target-Raten, Immunogenität der neuen Enzyme, Langzeitstabilität der Insertion). Die Übersetzung von Zellkultur zu Säugetierorganismus ist notorisch schwierig – bei CRISPR dauerte es Jahre, bis erste klinische Anwendungen möglich waren. - Sicherheitsfragen
Die Insertion großer DNA-Abschnitte birgt Risiken: mögliche Insertionsmutagenese, Aktivierung von Onkogenen, epigenetische Störungen oder Immunreaktionen gegen die neuartigen Enzyme. Die „safe-harbour“-Sites sind neu definiert – ihre Langzeitsicherheit ist unbekannt. Historisch scheiterten viele Gen-Insertion-Ansätze (z. B. Retroviren in der SCID-Therapie) genau an diesen Punkten. - Reproduzierbarkeit und Transparenz
Das Paper ist zwar ko-autoriert von NVIDIA und Microsoft, doch der vollständige Datensatz BaseData™ bleibt proprietär. Die Modelle sind nicht open-source. Dies wirft Fragen nach unabhängiger Validierung auf – ein Problem, das in der KI-Biotech-Branche zunehmend kritisiert wird. - Ethische und globale Implikationen
Der Datensatz stammt aus 28 Ländern – darunter vermutlich viele mit schwachen Biodiversitäts- und Datenschutzregelungen. Die Frage der Benefit-Sharing mit Ursprungsländern indigener Gemeinschaften ist offen. Gleichzeitig profitiert ein in London und Cambridge ansässiges Unternehmen mit NVIDIA-Backing – ein klassisches Nord-Süd-Gefälle in der Biotech. - Zeitlicher Horizont
Selbst optimistisch gerechnet liegen erste klinische Studien mindestens 4–7 Jahre entfernt. Die Pipeline wird als „emerging“ bezeichnet – also noch sehr früh.
Fazit: Technisch beeindruckend – therapeutisch noch weit entfernt
Basecamp Research hat mit aiPGI™ und EDEN einen echten wissenschaftlichen Sprung vollzogen. Die Kombination aus massiver evolutionärer Datenbasis, Frontier-AI und gezieltem Protein-Design könnte langfristig die Grenzen der Gentherapie neu definieren – weg von kleinen Edits hin zu echter programmierbarer Genom-Programmierung.
Gleichzeitig ist die Ankündigung typisch für die aktuelle Biotech-Hype-Welle: Große Worte, beeindruckende In-vitro-Zahlen, prominente Partner (NVIDIA), aber noch kein einziger Beweis in vivo oder in der Klinik. Die Geschichte der Gentherapie ist voll von „game-changing“-Technologien, die Jahre oder Jahrzehnte brauchten – oder scheiterten.
Für Patienten mit Krebs oder schweren Erbkrankheiten ist dies ein Hoffnungsschimmer. Für die Wissenschaft eine spannende Entwicklung. Für Kritiker ein weiteres Beispiel dafür, wie proprietäre KI und geschlossene Daten die Reproduzierbarkeit und demokratische Kontrolle der Biotechnologie bedrohen.
Der wahre Test kommt erst: in Mäusen, in Affen – und irgendwann, vielleicht, beim Menschen.
Der Artikel erschien im Original bei LabNews Media LLC
Redaktion: X-Press Journalistenbüro GbR
Gender-Hinweis. Die in diesem Text verwendeten Personenbezeichnungen beziehen sich immer gleichermaßen auf weibliche, männliche und diverse Personen. Auf eine Doppel/Dreifachnennung und gegenderte Bezeichnungen wird zugunsten einer besseren Lesbarkeit verzichtet.
Meistgelesen
 Interview: KKH Vorstandsvorsitzender Dr. Wolfgang Matz über Abrechnungsbetrug, KI und die Zukunft der GKV Im NACHGEFRAGT-Interview mit MedLabPortal spricht Dr. Wolfgang Matz, Vorstandsvorsitzender der KKH K...
Interview: KKH Vorstandsvorsitzender Dr. Wolfgang Matz über Abrechnungsbetrug, KI und die Zukunft der GKV Im NACHGEFRAGT-Interview mit MedLabPortal spricht Dr. Wolfgang Matz, Vorstandsvorsitzender der KKH K...- Psychotherapie: GKV-Spitzenverband plant pauschale Honorarkürzung in Höhe von zehn Prozent Der Berufsverband unith e.V. warnt vor einer drohenden pauschalen Kürzung der Honorare für psychothe...
- Lebensretter Labormedizin: „In der Regel sollte für Notfälle spätestens nach 60 Minuten ein Ergebnis vorliegen.“ Am 11.2 ist der Tag des Notrufs - doch für die Labormedizin ist es nur einer von 365 Tagen, an denen...



